오늘은 오차 역전파법 신경망을 파이썬으로 구현해 볼 겁니다!
확률적 경사 하강법을 이용한 2층 신경망 미니배치 학습 구현
간단한 신경망 학습 구현을 위해 확률적 경사 하강법을 이용한 미니배치 학습 방법을 활용하는 예제입니다. 이번 글에서는 MNIST 데이터셋을 사용하여 학습을 수행할 거고 신경망은 은닉층이 1개
huangdi.tistory.com
시작하기에 앞서 이전 포스트에서 정리했던 신경망 학습의 순서 중 오차역전파법 Backpropagation이 어느 단계에 해당하는 지 봅시다.
|
(1) 미니배치 (2) 기울기 산출 (3) 매개변수 갱신 (4) (1)에서 (3) 단계를 반복한다. |
오차역전파법은 2단계인 기울기 산출 단계에서 이용됩니다. 이전 포스트에서는 수치 미분을 사용하여 기울기를 구했습니다. 하지만 수치 미분을 이용하면 계산 시간이 오래 걸려서 더 효율적으로 기울기를 구하기 위해 오차역전파법을 사용하려고 합니다.
오늘의 신경망 구현 예제에서도 이전 포스트와 같이 아주 간단한 2층 신경망을 구현할 것이고, 이전에 정의한
TwoLayerNet 클래스를 수정하여 구현합니다. (본 포스트에서는 Deep Learning from Scratch의 코드를 이용합니다.)
오차역전파법을 사용하면서 주목해야 할 부분은 아래 주석처리로 ************ 표시를 한 부분들입니다.
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
import numpy as np
from common.layers import *
from common.gradient import numerical_gradient
from collections import OrderedDict
# OrderedDict은 순서가 있는 딕셔너리로 추가한 순서를 기억합니다.
# 순전파 때는 추가한 순서대로 각 계층의 forward()메소드 호출하면 되고,
# 역전파 때는 계층을 반대의 순서로 호출하기만 하면 됩니다.
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std = 0.01):
# 가중치 초기화
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
# 계층 생성 ***************************************
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.lastLayer = SoftmaxWithLoss()
# 인식 결과 얻는 처리 ***************************
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
# x : 입력 데이터, t : 정답 레이블
def loss(self, x, t):
y = self.predict(x)
return self.lastLayer.forward(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1 : t = np.argmax(t, axis=1) # 확률이 가장 높은 원소의 인덱스 얻기
# 신경망이 예측한 답변과 정답 레이블을 비교하여 맞은 경우를 세서 더하고
# 전체 이미지 숫자로 나눠 정확도를 구한다
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# x : 입력 데이터, t : 정답 레이블
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
# 기울기 얻는 처리 ********************
def gradient(self, x, t):
# forward 순전파 *******
self.loss(x, t)
# backward 역전파 **********
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 결과 저장
grads = {}
grads['W1'], grads['b1'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W2'], grads['b2'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
위에서 정의한 TwoLayerNet 클래스를 이용해서 신경망 학습을 구현하면 아래와 같습니다.
# coding: utf-8
import sys, os
sys.path.append(os.pardir)
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
# 데이터 읽기
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 기울기 계산
#grad = network.numerical_gradient(x_batch, t_batch) # 수치 미분 방식
grad = network.gradient(x_batch, t_batch) # 오차역전파법 방식(훨씬 빠르다)
# 갱신
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
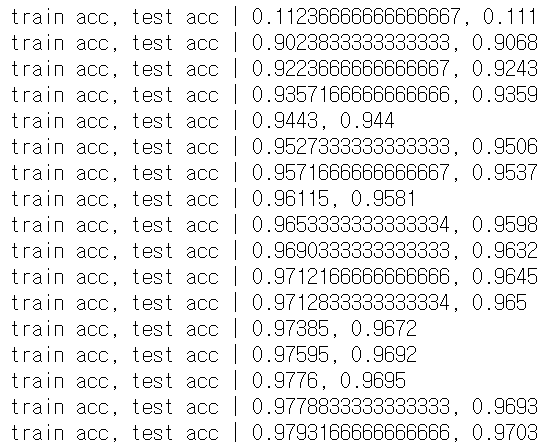
print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))
# 그래프 그리기
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, label='train acc')
plt.plot(x, test_acc_list, label='test acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()위 코드를 실행한 결과를 살펴보면 다음과 같습니다.
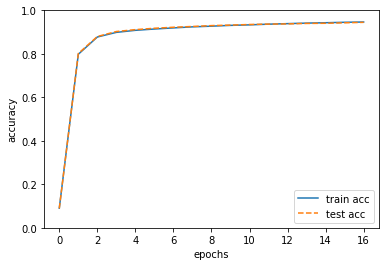
동작을 계층으로 모듈화한 덕분에, ReLU, Softmax-with-Loss, Affine, Softmax 계층을 자유롭게 조합하여 원하는 신경망을 만들 수 있습니다. 모든 계층에서 forward와 backward 메소드를 구현하여 forward로는 데이터를 순방향으로 전파하고, backward로는 가중치 매개변수의 기울기를 효율적으로 구할 수 있었습니다.
그럼 기울기를 구할 때 수치 미분 방법은 비효율적이기 때문에 안 쓰나요?
오히려 오차역전파법을 구현할 땐 해석적 방법으로 여러 계산을 통해 구현하기 때문에 실수가 있을 수 있어서
수치 미분 방법을 이용한 학습법과 결과를 비교해서 검증을 하기도 합니다.
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
import numpy as np
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
# 데이터 읽기
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
x_batch = x_train[:3]
t_batch = t_train[:3]
grad_numerical = network.numerical_gradient(x_batch, t_batch)
grad_backprop = network.gradient(x_batch, t_batch)
# 각 가중치의 절대 오차의 평균을 구한다.
for key in grad_numerical.keys():
diff = np.average( np.abs(grad_backprop[key] - grad_numerical[key]) )
print(key + ":" + str(diff))
| 수치 미분과 오차역전파법의 결과 오차가 0이 되는 일은 드뭅니다. 컴퓨터가 할 수 있는 계산의 정밀도가 유한하기 때문입니다(32비트 부동소수점 등). 이 정밀도이 한계 때문에 오차는 대부분 0이 되지는 않지만, 올바르게 구현했다면 0에 가까운 작은 값이 됩니다. 만약 그 값이 크면 오차역전파법을 잘못 구현했다고 의심해봐야 합니다. |
[출처] Deep Learning from Scratch, ゼロ から作る
'Computer Science > Deep Learning' 카테고리의 다른 글
| [비전공자용] [Python] Xavier Initialization (Xavier 초기화) & He Initialization (He 초기화) (0) | 2020.07.10 |
|---|---|
| [비전공자용] [Python] 모멘텀, AdaGrad, Adam 최적화기법 (0) | 2020.07.09 |
| [비전공자용] 확률적 경사 하강법 SGD 의 단점 (0) | 2020.07.08 |
| [비전공자용] [Python] 확률적 경사 하강법을 이용한 2층 신경망 미니배치 학습 구현 (0) | 2020.07.07 |
| [비전공자용] [Python] 머신러닝과 딥러닝 구분 (3) | 2020.07.03 |



