SGD란?
이전 포스트에서는 최적의 매개변수 값을 찾는 단서로 매개변수의 기울기(미분)을 이용했습니다.
이 방법을 확률적 경사 하강법, 즉 Stochastic Gradient Decent (SGD) 라고 합니다.
SGD의 수식은 아래 식과 같이 쓸 수 있습니다.
여기에서 W 는 갱신할 가중치 매개변수, L은 손실함수를 나타내고 η 는 학습률 learning rate,
∂L/∂W은 W 에 대한 손실함수의 기울기를 나타냅니다.

즉, SGD는 기울어진 방향으로 일정 거리만 가겠다는 단순한 방법입니다.
SGD를 파이썬 코드로 간단히 구현하면 다음과 같습니다.
import numpy as np
class SGD:
"""확률적 경사 하강법(Stochastic Gradient Descent)"""
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
SGD의 단점
SGD 방법은 굉장히 단순한 최적화 기법입니다. 여기서 최적화 Optimization란 손실함수의 값을 최소로 하는 매개변수를 찾는 과정을 의미합니다. 단순하면서 구현도 쉽지만, 문제에 따라 아주 비효율적일 때가 많습니다.
간단히 예를 들어서 아래 함수의 최솟값을 구하는 문제를 SGD를 이용해서 풀어본다고 합시다.

Wolfram Alpah 사이트에서 그래프를 확인해보면 다음과 같은 타원형 포물선 Elliptical Paraboloid 형태를 가진다는 것을 알 수 있습니다.

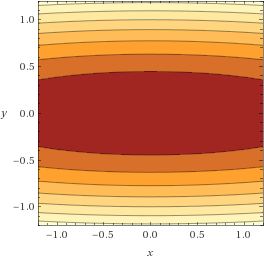

함수에 SGD를 적용하기 위해 함수 f(x,y)의 기울기의 음수값을 그래프로 나타내보면 (-∂f/∂x, -∂f/∂y)는 바로 위 기울기 갱신그래프와 같이 기울기 변화 방향을 보여준다. 함수의 global 최솟값이 되는 지점은 (0, 0)인데 기울기의 대부분이 (0, 0)을 향하기 보다는 y=0, 즉 x축을 향하는 것을 볼 수 있다.
SGD 탐색을 시작하는 초깃값을 (x, y) = (-7.0, 2.0)이라고 하고 최솟값인 (0, 0)으로의 최적화 갱신 경로를 구해보면 아래와 같이 지그재그 그래프를 그리는 것을 알 수 있다.

순간순간 기울기에 따라 방향을 결정하고 탐색을 하기 때문에 굉장히 비효율적으로 최솟점을 찾아가는 것을 볼 수 있습니다.
이러한 SGD의 단점을 개선하기 위해 다음 포스터부터 모멘텀, AdaGrad, Adam라는 세가지 방법을 소개할 예정입니다.
[출처] Deep Learning from Scratch, ゼロ から作る
'Computer Science > Deep Learning' 카테고리의 다른 글
| [비전공자용] [Python] Xavier Initialization (Xavier 초기화) & He Initialization (He 초기화) (0) | 2020.07.10 |
|---|---|
| [비전공자용] [Python] 모멘텀, AdaGrad, Adam 최적화기법 (0) | 2020.07.09 |
| [비전공자용] [Python] 오차역전파법 Backpropagation 신경망 구현 (0) | 2020.07.08 |
| [비전공자용] [Python] 확률적 경사 하강법을 이용한 2층 신경망 미니배치 학습 구현 (0) | 2020.07.07 |
| [비전공자용] [Python] 머신러닝과 딥러닝 구분 (3) | 2020.07.03 |



